北京城建设计集团杭州分院 · AI培训
AI赋能设计
从认知到行动
不是IT技术课,而是AI赋能设计工作的认知升级与实操指南
不是IT技术课,而是AI赋能设计工作的认知升级与实操指南
以Anthropic为镜,看AI编程的真实进化速度
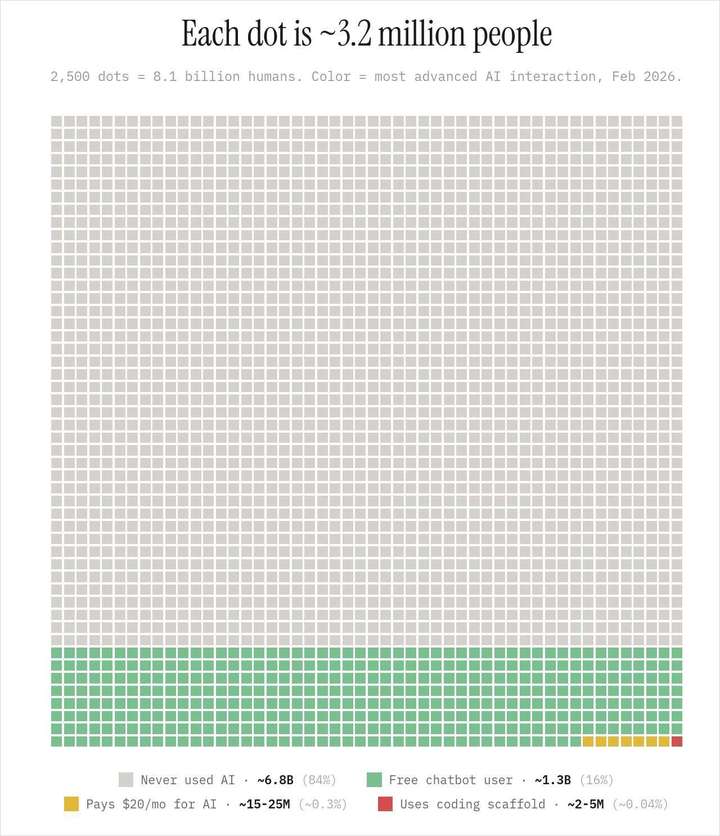
💡 听说过的举手:先对齐语言,再看体系时不懵
用哪一层决定了AI是"玩具"还是"工具"
| 层级 | 类型 | 代表工具 | 关键词 | 对应场景 |
|---|---|---|---|---|
| Level 1 | Prompt工具 | DeepSeek、通义千问 | 你问它答,一轮结束 | 规范检索、摘要 |
| Level 2 | 工作流工具 | Coze、Dify | 你画路线,它跑全程 | 新媒体工作流 |
| Level 3 | AI编程工具 | VSCode+Cline、Codex | 你提它写,从辅助到原生 | Vibe Coding |
| Level 4 | 全自动Agent | Hermes、OpenClaw | 你定目标,它交付产品 | 完整应用交付 |
| Level 5 | AI操作助理 | 悟空、Marvis | 你下指令,操作电脑执行 | 跨软件操作 |
对话即用,零门槛
提示词四要素:角色 + 任务 + 背景 + 要求
把多个步骤串成流水线,让AI“专家团”自动协作
将复杂任务拆解为7个标准动作,由不同角色的AI专家(Agent)接力完成
你从“写代码的人”变成“审代码的人”
你定目标,它交付产品
模型+框架融合的终极形态,自主操作电脑
| 落地阶段 | 推荐层级 | 具体场景 | 预期效果 |
|---|---|---|---|
| 即时可用 | Level 1 | 用DeepSeek处理规范检索、方案起草摘要 | 单点提效 |
| 短期部署 | Level 2 | 用Dify搭建内部设计规范问答系统 | 知识库可用 |
| 中期推进 | Level 2-3 | 工作流自动化审图,AI辅助开发内部工具 | 流程自动化 |
| 长期探索 | Level 4-5 | 全自动Agent交付产品,跨软件自动操控 | 全自动化 |
没有脚手架的自进化一定会出事
| AI擅长 | 处理海量文档、生成初稿、模式图纸比对、自动化 |
| AI不擅长 | 突破性创新决策、多专业复杂协调 |
| 绝不可做 | 替工程师签字、最终安全指标审核、向公有大模型传涉密图 |
| 工具 | 特点与定位 | 上手难度 |
|---|---|---|
| 腾讯IMA | 微信生态内拖入文档直接提问 | ⭐极简 |
| 千问知识库 | 网页端开箱即用的轻量级建库 | ⭐极简 |
| Dify | 可视化编排流,接多模型API | ⭐⭐进阶 |
| AnythingLLM | 全本地部署,适合极高保密要求 | ⭐⭐进阶 |
| Kimi | 单次处理200万字(标书/合同专用) | ⭐极简 |
解决参数散落、查询靠问人的痛点
| 模型规模 | 📦 权重底线 | 🌊 显存要求 | 推荐GPU方案 | 体验与适用场景 |
|---|---|---|---|---|
| 7B - 8B | 约4.5GB - 5GB | 8GB | RTX 4060 (8G) | 个人PC极速响应:基础代码补全、简单问答、个人知识库 |
| 14B - 16B | 约8.5GB - 10GB | 12GB - 16GB | RTX 4060 Ti (16G版) | 综合能力均衡:10人以内小团队,能够处理中等长度的文档分析和RAG检索 |
| 32B - 34B | 约18GB - 20GB | 24GB | RTX 4090 (24G) | 高性价比生产力:处理复杂推理、长文本编程、专业领域深度的极佳底座 |
| 70B - 72B | 约38GB - 40GB | 96GB (高并发必须) | 两张RTX 6000 Ada (共96G) | 企业级核心:高并发,复杂Multi-Agent协作底层模型 |
工具链路:Ollama/vLLM(引擎) → bge-m3(向量化) → Dify(编排) → OpenWebUI(前端)
解决策略:强制RAG知识溯源、输出结果必带来源标注、核心节点人工签审。
遇到任何AI工具,先灵魂三问